
Raguelさんのブログ
ブログ
GraniでRSS非対応サイトの更新通知を得る

Raguelさん
更新:2008/3/29 15:59投稿:2008/3/29 15:59
先日、RSS非対応サイトのRSSフィードを取得する方法を紹介したところ、コージー様から素晴らしい対応方法をご教示いただきました。
コメントのままでは情報が埋没しかねないので、その方法をコラムにして残しておくことにします。
コージー様の方法を簡単に言えば、RSSリーダーにHeadline-Readerを使用する、ということです。
Headline-Readerには、RSSに対応しないホームページの更新通知を行う「HTML抽出機能」というものがあるらしい。
早速ぐぐってみたところ、これは「ホームページの新着情報一覧ページなどから追加された文字列リンクを抽出することによりRSSに対応しないホームページの更新検知を可能とする」機能との解説がありました。詳細は以下のリンク先の説明を読んでください。
Fenrir & Co. RSSに対応しないホームページの更新を知ることができる
Headline-Reader Plugin RC2 と Grani1.2 を公開
技術的なことは良く判りませんが、説明文を読む限りではRSSフィードを生成して受け取るという方式ではないようです。ただ、重要なのはRSS非対応サイトの更新を知ることなので、実現方法は大した問題ではありませんね。
ここで気になるのは、この超絶便利機能Headline-Readerを実装するRSSリーダー/ブラウザの種類。私が調べた限りでは、Headline-Reader(有料版)、Sleipnirのプラグイン、そしてGraniの3種類のようです。
残念ながら、無料版のHeadline-Reader-Liteには当機能はないようでした。ダウンロードしてざっと使ってみただけなので間違っているかも知れませんが。
で、この3種類の中でも特にイチオシなのは、ブラウザソフトのGrani。
その理由は、Headline-Reader機能を実装している上に、単なるブラウザとして見ても、非常に軽量かつ高速だからです。
インターネット高段者?ならばSleipnir+プラグインの選択肢が良いのかも知れませんが、私のようにRSS初心者には高機能すぎてあまりお勧めできません。
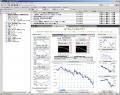
Graniを起動してHeadline-Readerのパネルを開くと、下のイメージ図のように3ペイン構成になります。
左側の部分がHeadline-Readerパネル、上段がフィードの明細で、下段がブラウザです。
GraniでHTML抽出機能を利用する手順は、
1.RSS非対応サイトのURLをコピーしておく
2.Headline-Readerパネル部分で右クリック
3.「フィードの追加」を選択
4.コピーしたURLを指定
5.HTML抽出機能のチェックボックスをオンにする
これだけ。
上記イメージ図でフィード明細部分に表示されているのが、HTML抽出機能を使って表示した日経ネットの(擬似)フィードの明細です。擬似フィードといっても、見た目はRSSフィードを受け取っているのとなんら違いはないのがお判り頂けると思います。
ちなみに、フィードを受け取る間隔は標準で30分。最低は15分で、自由に設定変更可能です。
ただ、必ずしもこのタイミングで確実にフィードを受け取れるわけではないらしい。
というのは、ブルームバーグ(正確にはinfoseekマネー)のフィード設定を15分にしていて、その間に元サイトにニュースがアップされているにもかかわらず、フィードが入ってこないという現象が起きているからです。今のところ、だいたい30分〜1時間遅れといった感じでしょうか。
この原因は今のところ不明。もしわかる方がいましたら、教えてください。
最後に、HTML抽出機能を利用する上で重要な機能となるフィルタリング機能について補足しておきましょう。これは、コージー様の説明が判りやすいので、そのまま引用させて頂きます。
-------------------------------------------------------------------
Headline-Readerにはフィルタリング機能があり、不要なリンク先を除外したり、必要なリンク先のみ抽出できます。
http://www.infomaker.jp/headline/extract.htm
http://www.infomaker.jp/headline/tree.htm#keyword
例えば、日経ヴェリタスのサイトですが
http://veritas.nikkei.co.jp/scramble/index.aspx
記事以外の不要なリンク先まで読み込んでしまうことがあります。そこで記事のリンクを見ると必ず「日付」があることがわかります。したがってフィルタ文字を「*/*/*」と指定することにより、必要記事のリンク先だけ、読み取ることができます。
他にも例えば、ドリームバイザーはNSJ日本証券新聞に動画を配信していまが
http://www.nsjournal.jp/index.php
これもフィルタ文字を「*月*日(*)」と指定することにより、ドリームバイザーの動画のリンク先のみ抽出することができます。
また、タイトルだけではなく、カテゴリーでも抽出することができきます。
例えばFC2は新着記事のRSSフィードを配信していますが
http://blog.fc2.com/newentry.rdf
これもフィルタ文字に「株式・投資・マネー」と指定することにより、株式・投資・マネーのジャンルの記事のみ読み取ることができます。
このようにHeadline-ReaderでRSS非対応サイトを読むことができ、さらにフィルタリング機能により必要なリンク先のみ抽出することができますが、範囲指定をしなければならないページはgooフィードメーカーを使ったほうが便利です。
例えば楽天ブログに「株式投資でお小遣いを増やそう」というテーマがあります。
http://plaza.rakuten.co.jp/thm/42093/g1200/
このページの右側には新着テーマの不要なリンクがあり、左側の必要な部分のみをHeadline-Readerで指定することは不可能です。このような範囲指定が必要なページはgooフィードメーカーを使用することにより解決します。
http://money.www.infoseek.co.jp/MnJbn/jbnindex/?pubid=10
-------------------------------------------------------------------
フィルタリング機能は、条件に合致する記事のみ読み取ります。これは、逆に言えば正確に条件を指定しないと一切フィードを受け取れなくなるという意味であり、注意する必要があります。
(これで私は失敗しました^^;)
ちなみに、上のイメージ図に示した日経ネットのフィードではフィルタリング機能は使っていません。使わなくてもそれほど問題にならない場合もあるので、まずは無指定から始めるのが良いのでしょう。
長々と書きましたが、言いたいことは「GraniのHTML抽出機能」はとにかく凄いということ。
そして、なんといってもGraniは速い。
クソ重たい当ブログも、結構早く読み込んでくれます^^;
IE7では動作しないチャートだけの更新機能もしっかり動いてくれますし。
「株で悩んだら見るブログ」を読むときにも、Graniは絶対オススメです!
Graniをダウンロードする方はこちら
クリックして頂けると励みになりますm(_ _)m
FC2 Blog Ranking[株式・投資]
コメントを書く
コメントを投稿するには、ログイン(無料会員登録)が必要です。